")

Kubernetes Probes
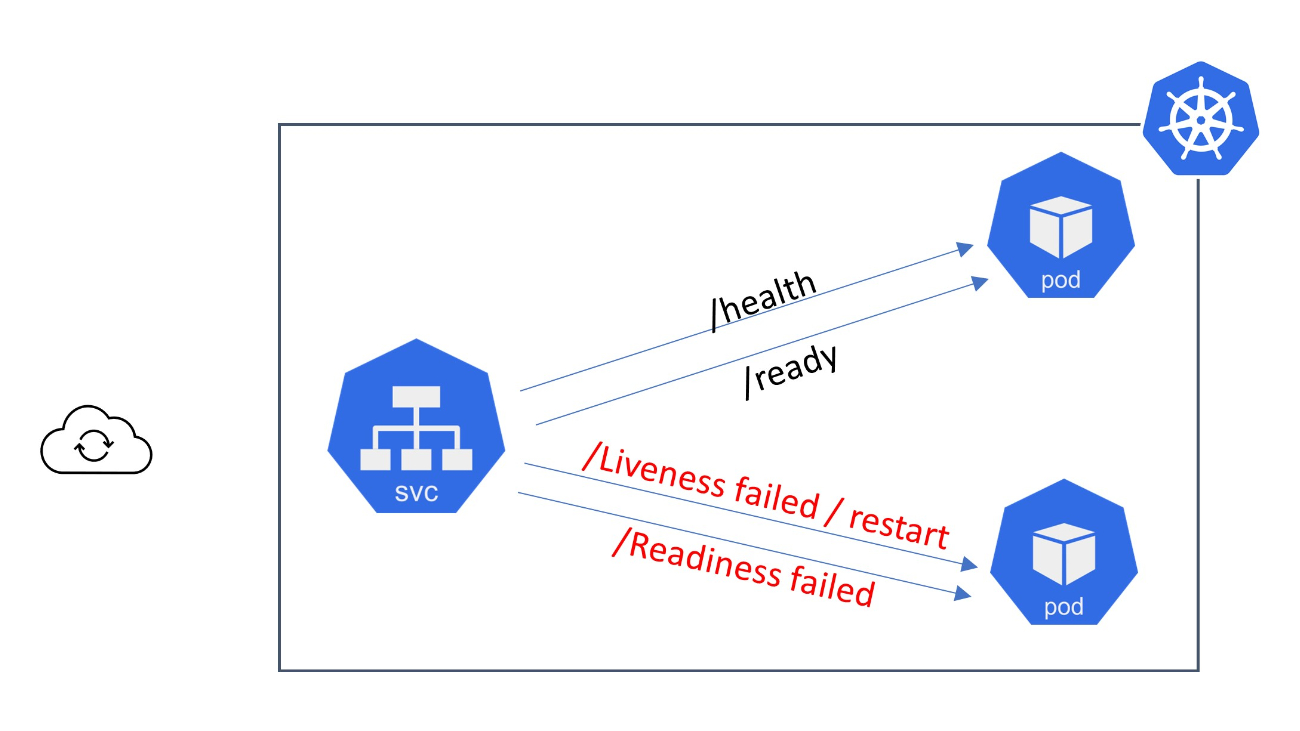
In Kubernetes, a probe is a mechanism used to determine the health and readiness of a container or application running within a pod. Probes are defined in the pod specification and are performed periodically to ensure the proper functioning of the application. Kubernetes supports three types of probes: liveness probes, readiness probes, and startup probes.
Liveness Probe:
A liveness probe determines if a container is still running and functioning correctly. If the liveness probe fails, Kubernetes considers the container to be unhealthy and takes appropriate action, such as restarting the container. Liveness probes are essential for applications that can encounter runtime issues or deadlock situations.
Readiness Probe:
A readiness probe determines if a container is ready to receive incoming network traffic and serve requests. It ensures that the container has completed its initialization process and is prepared to handle requests. If the readiness probe fails, Kubernetes removes the container's IP address from the service's list of endpoints, directing traffic to other healthy containers.
Startup Probe:
A startup probe is used to determine if a container's application has started successfully. It is mainly useful for scenarios where an application takes a longer time to start but can eventually become healthy. Unlike liveness and readiness probes, the result of a startup probe does not affect the container's readiness or liveness status. Once the startup probe succeeds, the liveness and readiness probes take over.
For each probe, you can define various parameters such as the probe type (HTTP, TCP, or Exec), the probe's timeout, the interval between probe checks, the number of consecutive failures before considering the probe as failed, and the success criteria.
Probes provide Kubernetes with the ability to manage container health and readiness automatically, allowing for better resilience, self-healing, and efficient routing of network traffic within a cluster.
Let's describe each of them in more detail:
Liveness Probe:
A liveness probe is a mechanism used to determine if a container is still running and functioning correctly. It periodically checks the health of a container's application or process and takes appropriate action if the probe fails, such as restarting the container.
Here are the key aspects of Kubernetes liveness probes:
Probe Types: Kubernetes supports four types of liveness probes: HTTP, TCP, Exec and gRPC. You can choose the type that best suits your application's needs.
- HTTP Probe: It sends an HTTP GET request to a specified endpoint on a container's IP address and port. If the endpoint returns a successful HTTP status code (2xx or 3xx), the probe considers the container as healthy. Otherwise, it assumes the container is unhealthy.
- TCP Probe: It attempts to open a TCP connection to a specified port on the container. If the connection is successfully established, the container is considered healthy. Otherwise, it is considered unhealthy.
- Exec Probe: It executes a specified command inside the container. If the command exits with a zero status code, the container is considered healthy. Otherwise, it is considered unhealthy.
- gRPC Probe: Since Kubernetes version 1.24, the gRPC handler can be configured to be used by the kubelet for application lifetime checking. To configure checks that use gRPC, you must enable the GRPCContainerProbe function gate. You must configure the port to use a gRPC probe, and if the health endpoint is configured on a non-default service, you also need to specify the service.
Timing and Parameters: You can configure various parameters for liveness probes, including:
- initialDelaySeconds: The delay in seconds before the first liveness probe is performed. This allows time for the container to start up.
- periodSeconds: The time interval between consecutive liveness probes. It defines how frequently the probe should be performed.
- timeoutSeconds: The maximum amount of time given to each liveness probe to complete. If the probe exceeds this timeout, it is considered failed.
- failureThreshold: The number of consecutive failures allowed before considering the container as unhealthy and triggering the defined action (e.g., container restart).
- successThreshold: The number of consecutive successful probes required to transition a container from an unhealthy to a healthy state. This parameter helps prevent quick flapping between unhealthy and healthy states.
Actions on Probe Failure: When a liveness probe fails, Kubernetes takes the specified action based on the pod's restart policy:
- If the pod has a RestartPolicy set to Always, Kubernetes restarts the container.
- If the pod has a RestartPolicy set to OnFailure or Never, Kubernetes does not restart the container, but the failed probe affects the pod's overall health status.
Liveness probes are crucial for detecting and recovering from issues that occur during runtime, such as application crashes or deadlock situations. By periodically checking the health of containers, Kubernetes can automatically handle unhealthy containers and ensure the overall availability and stability of your applications.
Here's an example of how you can define a liveness probe in a Kubernetes pod specification using an HTTP probe:
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-container
image: my-image:latest
ports:
- containerPort: 8080
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
failureThreshold: 3
timeoutSeconds: 5In this example, we have a pod with a single container named my-container. The container is using the my-image:latest image and exposes port 8080.
The container has a liveness probe defined. The liveness probe is configured as an HTTP probe that checks the /health endpoint on port 8080 of the container. If the endpoint returns a successful HTTP status code (2xx or 3xx), the probe considers the container as healthy. Otherwise, it assumes the container is unhealthy.
The liveness probe starts running after an initial delay of 15 seconds and is repeated every 10 seconds. The probe allows for a maximum of 3 consecutive failures before considering the container as unhealthy. Each probe has a timeout of 5 seconds, which means that if the probe does not receive a response within 5 seconds, it is considered failed.
When the liveness probe fails, Kubernetes takes the specified action based on the pod's restart policy. For example, if the pod has a RestartPolicy set to Always, Kubernetes will restart the container.
Please note that you would need to adjust the path, port, timing, and other parameters according to your specific application's requirements and setup.
Readiness Probe:
A readiness probe is a mechanism used to determine if a container is ready to receive network traffic and serve requests. It ensures that the container has completed its initialization process and is prepared to handle incoming requests. Readiness probes play a crucial role in enabling smooth traffic routing and load balancing within a Kubernetes cluster.
Here are the key aspects of Kubernetes readiness probes:
Probe Types: Similar to liveness probes, Kubernetes supports three types of readiness probes: HTTP, TCP, and Exec. You can choose the type that best fits your application's requirements.
- HTTP Probe: It sends an HTTP GET request to a specified endpoint on a container's IP address and port. If the endpoint returns a successful HTTP status code (2xx or 3xx), the probe considers the container as ready. Otherwise, it assumes the container is not ready.
- TCP Probe: It attempts to open a TCP connection to a specified port on the container. If the connection is successfully established, the container is considered ready. Otherwise, it is considered not ready.
- Exec Probe: It executes a specified command inside the container. If the command exits with a zero status code, the container is considered ready. Otherwise, it is considered not ready.
Timing and Parameters: You can configure various parameters for readiness probes, including:
- initialDelaySeconds: The delay in seconds before the first readiness probe is performed. This allows time for the container to start up and complete its initialization process.
- periodSeconds: The time interval between consecutive readiness probes. It defines how frequently the probe should be performed.
- timeoutSeconds: The maximum amount of time given to each readiness probe to complete. If the probe exceeds this timeout, it is considered failed.
- failureThreshold: The number of consecutive failures allowed before considering the container as not ready. When the failure threshold is reached, the container's IP address is removed from the service's list of endpoints, directing traffic away from the container.
Actions on Probe Failure: When a readiness probe fails, Kubernetes considers the container as not ready and takes appropriate actions based on the pod's configuration:
- If a pod is part of a service and its readiness probe fails, Kubernetes removes the pod's IP address from the service's list of endpoints. This ensures that the traffic is not directed to the container until it becomes ready again.
- If the readiness probe fails and the pod has a RestartPolicy set to Always, Kubernetes does not automatically restart the container. Instead, it waits for the container to become ready based on the defined probe configuration.
Readiness probes are crucial for ensuring that only healthy and fully initialized containers receive traffic, minimizing disruptions and providing smooth service discovery and load balancing capabilities within a Kubernetes cluster.
Here's an example of how you can define a readiness probe in a Kubernetes pod specification using an HTTP probe:
In this example, we have a pod with a single container named my-container. The container is using the my-image:latest image and exposes port 8080.
The container has a readiness probe defined. The readiness probe is configured as an HTTP probe that checks the /health endpoint on port 8080 of the container. If the endpoint returns a successful HTTP status code (2xx or 3xx), the probe considers the container as ready. Otherwise, it assumes the container is not ready.
The readiness probe starts running after an initial delay of 10 seconds and is repeated every 5 seconds. The probe allows for a maximum of 3 consecutive failures before considering the container as not ready. Each probe has a timeout of 2 seconds, which means that if the probe does not receive a response within 2 seconds, it is considered failed.
When the readiness probe fails, if the pod is part of a service, Kubernetes removes the pod's IP address from the service's list of endpoints. This ensures that traffic is not directed to the container until it becomes ready again.
Please note that you would need to adjust the path, port, timing, and other parameters according to your specific application's requirements and setup.
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-container
image: my-image:latest
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3Startup Probe:
The startup probe is a type of probe introduced in Kubernetes version 1.16 to handle scenarios where containers take a longer time to start up but can eventually become healthy. It is particularly useful for applications that require a significant initialization process or have dependencies that need to be fully established before the application is considered ready.
Unlike liveness and readiness probes, the result of a startup probe does not directly affect the container's readiness or liveness status. The purpose of the startup probe is to determine if the container's application has started successfully, signaling that it is progressing towards a healthy state. Startup probe is fired only once. This happens when a Pod is scheduled.
Startup probe has higher priority over the two other probe types. Until the Startup Probe succeeds, all the other Probes are disabled.
Here are the key characteristics of a startup probe:
Probe Type: Like other probes in Kubernetes, the startup probe supports three types: HTTP, TCP, and Exec. You can choose the type that best suits your application's startup process.
Timing and Parameters: Similar to liveness and readiness probes, you can configure various parameters for the startup probe, including the probe's timeout, the interval between probe checks, the number of consecutive failures before considering the probe as failed, and the success criteria.
Transition to Liveness and Readiness: Once the startup probe succeeds, the liveness and readiness probes take over. This means that after the container passes the startup probe, its readiness and liveness status will be evaluated based on the respective configurations for those probes.
By introducing the startup probe, Kubernetes provides a way to differentiate between containers that are still initializing and those that have encountered a runtime error. It allows Kubernetes to delay marking a container as unhealthy or unready until it has had a reasonable chance to start up successfully. This helps to avoid false negatives and unnecessary restarts of containers that may just require more time to complete their initialization process.
Here's an example of how you can define a startup probe in a Kubernetes pod specification using an HTTP probe:
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-container
image: my-image:latest
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
startupProbe:
httpGet:
path: /startup
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
failureThreshold: 30In this example, we have a pod with a single container named my-container. The container is using the my-image:latest image and exposes port 8080.
The pod has both a readiness probe and a startup probe defined. The readiness probe checks the /health endpoint on port 8080 to determine if the container is ready to receive traffic. It starts running after an initial delay of 10 seconds and is repeated every 5 seconds.
The startup probe, on the other hand, checks the /startup endpoint on port 8080 to determine if the container's application has started successfully. It starts running after an initial delay of 5 seconds and is repeated every 10 seconds. The startup probe allows for a maximum of 30 consecutive failures before considering the probe as failed.
Once the startup probe succeeds, the container's readiness and liveness will be evaluated based on the readiness probe's configuration.
Please note that you would need to adjust the paths, ports, and other parameters according to your specific application's requirements and setup.
Here are a few problems that can arise with Kubernetes probes:
- Misconfigured Probes: One common problem is misconfiguring the probes, such as specifying incorrect endpoints, ports, or paths. This can lead to false-positive or false-negative results, causing containers to be erroneously marked as unhealthy or ready.
- Insufficient Timeout: If the timeout for a probe is set too low, it might result in false failures. If the container takes longer to respond due to high load or complex initialization processes, the probe might time out and mark the container as unhealthy, triggering unnecessary restarts.
- Unresponsive or Slow Applications: Probes rely on the responsiveness of the application or process within the container. If the application is unresponsive or slow due to bugs, performance issues, or resource constraints, it can lead to false negatives and misjudgment of container health.
- Resource Constraints: In cases where probes put additional load on containers, such as HTTP requests or executing commands, it can consume resources and affect the performance of the application itself. This can result in delays in application responsiveness or increased resource utilization.
- Timing Issues: In certain scenarios, timing can be a challenge. For example, if the initial delay for a readiness probe is too short, the probe may start before the container's application has finished initializing. This can lead to false negatives and prevent the container from receiving traffic prematurely.
- Interference with Container Startup: If a liveness or readiness probe is too aggressive, it can interrupt the startup process of a container. For example, if the probe starts too early and triggers restarts during the initialization phase, it can prevent the container from properly completing its setup.
- Kubernetes probes are affected by restart policies. It is important to know that container restart policies are applied after probes. That is, your containers restartPolicy: Always (the default) or restartPolicy: OnFailure to allow Kubernetes to restart them after a failed probe.
Therefore, you should use the Never policy, then the container will remain in the failed state.
- Startup Delay: If the initial delay for a probe is set too short, it may start before the container/application has completed its initialization process. This can result in false negatives, as the container might not be fully ready to handle requests or respond to probes.
It's essential to carefully design and configure probes based on your specific application's characteristics and requirements. Regular monitoring, troubleshooting, and tuning of probe settings can help address these issues and ensure the accurate health and readiness detection of containers within a Kubernetes cluster.
It is important to know that the probes are controlled by the kubelet.
A disadvantage of the Liveness -Probe is that the responsiveness of a service may not be checked.
Furthermore, the change of the dynamic must be considered. In the course of time this can change.
An example of this: If a container responds a bit later because of a short load increase, the container may be restarted if you set the timeout time of the Liveness probe too short. Such a restart can cause other pods to have problems as well, since further Liveness Probe failures may then occur.
If you want to make sure that the containers are started reliably, you should set the option "intitialDelySeconds" rather more conservatively.
Another story to consider with probes is network latency. You must be careful when setting the timeouts.
How can you check the probes?
- for Readiness probe you can see this with kubectl get po
- you can check it with a describe to the pod: kubectl describe pod <pod name>
- kube-state-metrics: If you have kube-state-metrics deployed in your cluster, you can use it
to query the status of probes.
- Monitoring and Logging Tools: You can use monitoring and logging tools like Prometheus,
Grafana, or ELK Stack (Elasticsearch, Logstash, Kibana) to collect and visualize probe-related
metrics and logs.
- Container Runtime Interface (CRI) Tools: If you need to inspect the probe results at the container
runtime level, you can use CRI tools specific to your container runtime, such as docker stats for
Docker or crictl for containerd.
For more in-depth information, see the Kubernetes documentation:
Author: Ralf Menti
Read our latest Blogpost
