")

Introduction
In the fast-paced world of container orchestration, Kubernetes has established itself as the leading platform. It enables businesses to efficiently manage, scale, and automate their applications. While many organizations opt for Kubernetes, they face a major decision: choosing the right cluster topology.
A Kubernetes cluster consists of a collection of computers running containers, along with the associated services and resources. The cluster's topology describes how these resources are organized and interconnected. There are various topologies that can be chosen based on the organization's requirements and goals.
In this blog post, we will explore different Kubernetes cluster topologies and help you select the right architecture for your specific needs. We will consider various aspects, including scalability, availability, network configuration, security, and geographic distribution.
Whether you are just starting with Kubernetes or already operating a cluster and seeking to optimize its performance, this guide will provide valuable insights into the different options available to you. We will discuss the pros and cons of each topology and assist you in making the right decision to optimize your Kubernetes environment.
It is important to note that there is no one-size-fits-all solution. The choice of the right cluster topology depends on your organization's specific requirements. By understanding the various options and their impact on performance, scalability, and reliability, you can make the best possible decision.
So, let us dive into the world of Kubernetes cluster topologies and help you take your container orchestration to the next level!
Single Node Cluster
A single-node cluster is a cluster topology where all Kubernetes components are running on a single node. This is often used for testing or development setups where scalability and high availability requirements are not as critical as in a production environment.
Single-node clusters provide an easy way to test Kubernetes locally or develop small applications without the need for setting up a complex infrastructure. They are quick to set up and require minimal resources. However, they are not suitable for use in production environments as they do not offer high availability and their performance is limited.
Pros
Simple Setup: A single-node cluster is easy to set up and does not require complex configuration. It can be a good option for development environments or small applications where high scalability or fault tolerance is not required.
Cost Efficiency: Since only a single node is operated in the cluster, the costs for hardware, operation, and maintenance are lower compared to other cluster types.
Low Resource Consumption: A single-node cluster requires fewer resources as only one node is operated. This can be advantageous when resources are limited or the application has low resource requirements.
Cons
Lack of Fault Tolerance: A single-node cluster lacks redundancy or failover mechanisms. If the single node fails, all applications and services in the cluster are affected.
Limited Scalability: A single-node cluster can limit its resource capacity. As application requirements grow, it can be challenging to scale the cluster accordingly.
Restricted High Availability: Due to the absence of redundancy mechanisms, a single-node cluster can be vulnerable to downtime. Maintenance activities or hardware failures can impact the operation of applications.
Namespace Cluster

A Namespace Cluster is a cluster topology where different teams or applications are organized in separate namespaces. A namespace is a virtual cluster within a physical Kubernetes cluster that allows for resource isolation and management. Each team or application can have its own namespace in which they can provision and manage their resources.
The use of Namespace Clusters offers several advantages. It allows for easier organization and isolation of applications, facilitates resource allocation, and enables upgrades and maintenance activities without impacting other namespaces. Additionally, it facilitates the enforcement of access control policies and enhances cluster security.
Pros
Resource Isolation: By using Namespace Clusters, different teams or applications can isolate their resources in separate namespaces. This allows for better organization and management, as each entity can independently manage its own resources.
Access Control and Security: Namespace Clusters enable the enforcement of access control policies at the namespace level. This allows businesses to enhance the security of their applications and data by defining fine-grained access rights at the namespace level.
Easy Deployment and Scalability: Namespace Clusters facilitate the deployment of resources tailored to the specific requirements of each team or application. They enable independent scaling of resources for each namespace based on individual needs.
Cons
Management Complexity: Managing Namespace Clusters can be complex as multiple namespaces need to be managed simultaneously. It requires efficient organization and clear communication between different teams or applications.
Resource Constraint: Since Namespace Clusters are based on a single physical cluster, all namespaces share the available resources. Inappropriate usage or overutilization in one namespace can impact other namespaces.
Potential Single Point of Failure: If the physical cluster on which the Namespace Clusters are based experiences a failure, all namespaces are affected. It is important to implement measures for fault tolerance and redundancy to avoid such scenarios.
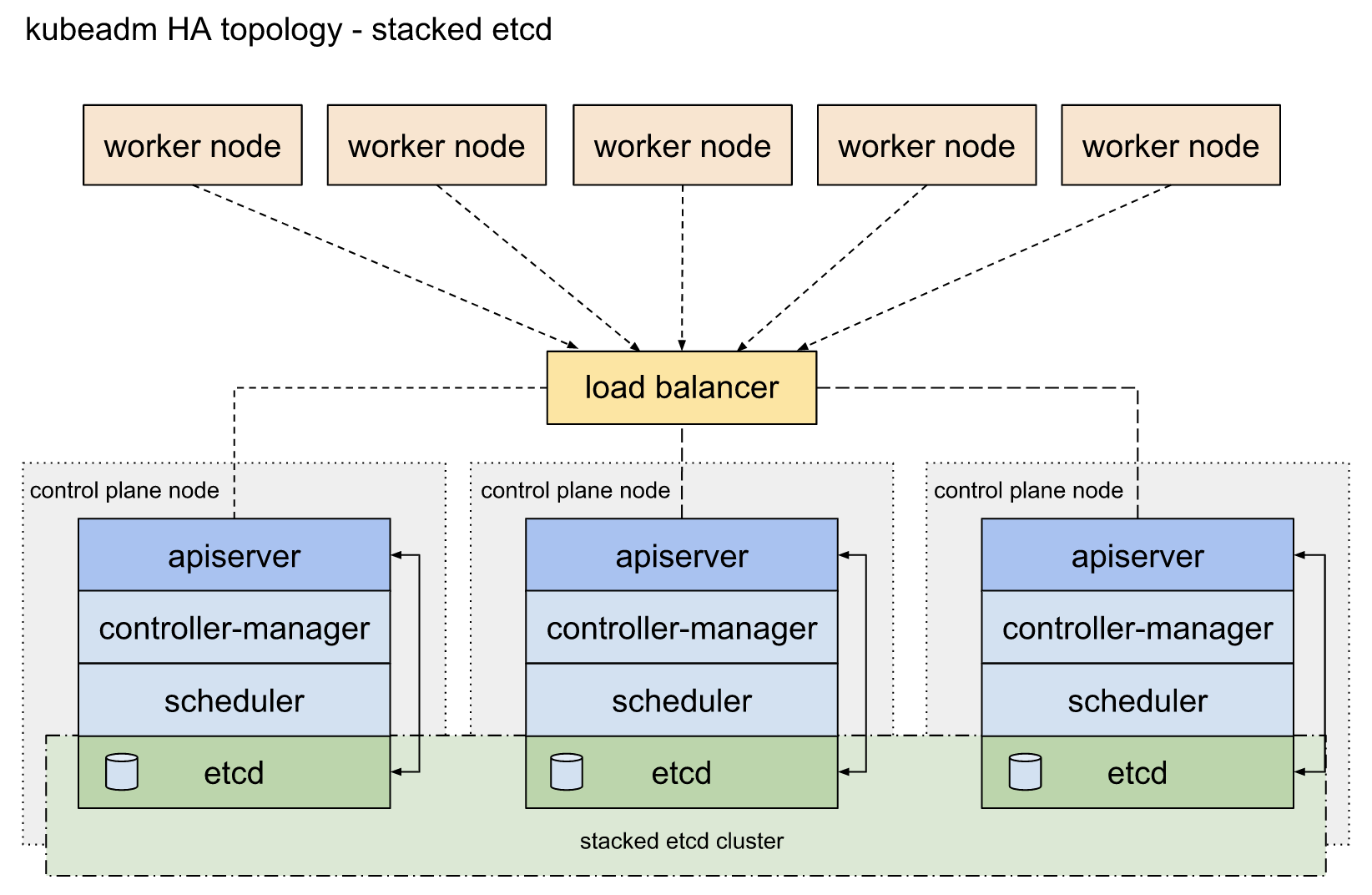
HA Cluster (Highly Available Cluster):
https://www.kubesphere.io/images/blogs/en/k8s-ha-practices/k8s-ha-strategy.png
A Highly Available Cluster, also known as an HA Cluster, is a cluster topology designed for high availability and fault tolerance. In an HA Cluster, the Kubernetes components are replicated across multiple nodes to ensure redundancy and load balancing.
An HA Cluster offers benefits such as continuous availability of applications, automatic recovery from failures, and scalability to handle growing workloads. By distributing the Kubernetes components across multiple nodes, the cluster can remain operational even during maintenance or upgrades. However, setting up an HA Cluster requires appropriate hardware and network infrastructure, as well as careful configuration of the components.
Pros
High Availability: HA (High Availability) Clusters provide a robust infrastructure to ensure continuous availability of applications. By distributing resources and workloads across multiple nodes and replicating data, fault tolerance is increased.
Automatic Recovery: HA Clusters are capable of automatically responding to failures and continuing operations on another node. This minimizes downtime and ensures seamless recovery of applications.
Scalability: HA Clusters allow for resource scaling to meet growing demands. By adding additional nodes, businesses can increase the performance and capacity of the cluster.
Cons
Complexity: Configuring and managing an HA Cluster requires technical expertise and careful planning. Mechanisms such as load balancing, data replication, and failover need to be implemented.
Cost: Operating an HA Cluster can come with higher costs, as multiple nodes and potentially specialized hardware or software are required to ensure availability.
Network Dependency: An HA Cluster heavily relies on a stable and reliable network connection. Poor network connectivity can impact the performance and availability of the cluster.
Seed Cluster
A Seed Cluster topology in Kubernetes is a special type of cluster that serves as a starting point for creating additional clusters. The Seed Cluster contains minimal configuration and resources to initialize and expand other clusters. It is an efficient method to ensure consistency and scalability across clusters.
The Seed Cluster provides a central control plane for managing configuration files, policies, and other resources used by the derived clusters. By using a Seed Cluster, businesses can simplify the management and deployment of clusters by providing a unified base and synchronizing configuration across all derived clusters.
Pros
Consistent Configuration: By using a Seed Cluster as a starting point, businesses can maintain a consistent configuration across all derived clusters. This ensures consistency and standardization across the clusters.
Efficient Scaling: Seed Clusters enable efficient scaling as they serve as a foundation for creating and expanding additional clusters. New clusters can be quickly and easily created based on the Seed Cluster configuration.
Centralized Management: A Seed Cluster provides a central control plane for managing configuration files, policies, and other resources. This simplifies the management and deployment of clusters as the central resources can be applied to all derived clusters.
Cons
Complexity of Setup: Setting up a Seed Cluster requires careful planning and configuration to ensure that all necessary resources and configuration details are taken into account.
Dependency on Seed Cluster: The availability and performance of the derived clusters depend on the availability and performance of the Seed Cluster. Any failure or impairment of the Seed Cluster can impact all derived clusters.
Scaling Limits: In the case of rapid growth or very large clusters, there may be scaling limits if the capacity of the Seed Cluster is not sufficient to meet the requirements of all derived clusters.
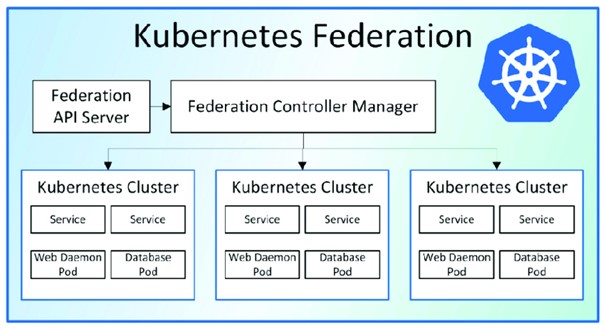
Federation Cluster
{kind=link}
A Federation Cluster, sometimes also referred to as a multi-Cluster, is a cluster topology where multiple Kubernetes clusters are connected and managed as a single entity. A Federation Cluster allows for the distribution and scaling of applications and resources across multiple clusters.
The use of a Federation Cluster provides flexibility and scalability, especially when applications need to be deployed across geographic locations. It enables efficient utilization of resources in different clusters and facilitates the management and deployment of applications on a global scale. However, configuring and managing a Federation Cluster requires additional complexity and careful planning to ensure smooth communication and coordination between the clusters.
Pros
Scalability across locations: By using a Federation Cluster, businesses can scale applications and resources across multiple geographic locations. This allows for efficient resource utilization and improved deployment of applications on a global scale.
Redundancy and fault tolerance: Federation Clusters offer increased redundancy as multiple clusters are interconnected. In case of failures in one cluster, applications can seamlessly continue running on other clusters, ensuring high availability.
Proximity to users: Deploying applications through Federation Clusters allows companies to position their applications closer to their users, reducing latency. This enhances user experience and enables faster data transfer.
Cons
Complexity of configuration and management: Setting up and managing a Federation Cluster requires additional complexity. Mechanisms for coordination, synchronization, and communication between the clusters need to be implemented.
Dependency on network connections: Federation Clusters heavily rely on reliable network connections to ensure efficient communication and coordination between the clusters. Poor network connectivity can impact performance and synchronization.
Potential increased latency: Since Federation Clusters are distributed across geographic locations, there may be increased latency, especially when synchronizing or transferring data between clusters. This can affect the performance of applications that require fast data transfer.
Georedundant Cluster
A georedundant cluster is a cluster topology based on geographic redundancy to ensure high availability and resilience against failures. In a georedundant cluster, Kubernetes components are replicated across multiple geographically distributed locations. This ensures that the cluster continues to function even if one location or region fails or is affected by a significant event.
The use of a georedundant cluster provides businesses with increased fault tolerance and business continuity. By distributing the cluster across different geographic locations, potential impacts of natural disasters, network outages, or other disruptions are minimized. Additionally, a georedundant cluster enables the fast and automatic recovery of applications at another location in case of a failure.
Pros
High Availability: Georedundant clusters provide increased fault tolerance as they are distributed across different geographic locations. Even if one location fails, applications can continue to operate seamlessly at another location.
Business Continuity: Geographic redundancy allows businesses to maintain operations even if a location or region is affected by a significant event. It enables fast and automatic recovery of applications at an alternate location.
Risk Mitigation: Georedundant clusters minimize the risk of data loss and disruptions caused by natural disasters, network outages, or other disruptions. By distributing the cluster across multiple locations, the impact on a single area can be reduced.
Cons
Complexity: The configuration and management of a georedundant cluster involve additional complexity. Mechanisms for data synchronization and secure communication between locations need to be set up.
Cost: Implementing a georedundant cluster typically incurs higher costs as infrastructure and resources need to be provisioned at multiple locations.
Latency: Due to the geographical distribution, increased latency can occur, especially when replicating data between locations.
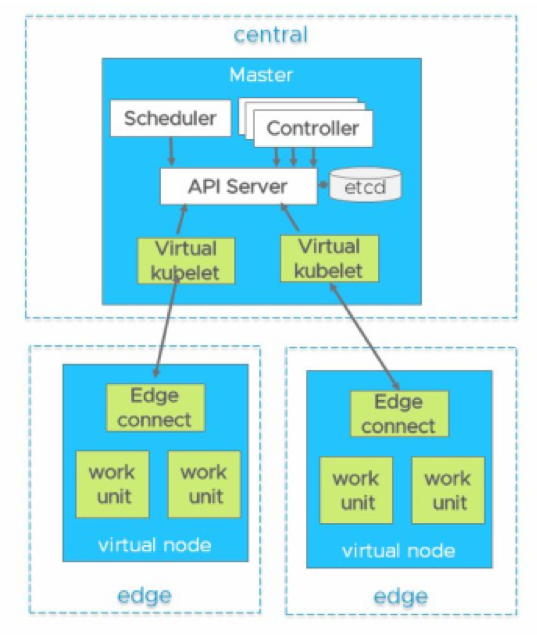
Edge Cluster
https://calsoftinc.com/blogs/wp-content/uploads/2019/08/Kubernetesedgepic5.png
An Edge cluster is a cluster topology specifically designed for deployment at the network edge, closer to end users or devices. Unlike centralized clusters typically operated in large data centers, Edge clusters are deployed closer to the locations where data is generated and needed.
The use of Edge clusters allows businesses to reduce latency and improve application performance by placing data processing and storage closer to users or devices. This is particularly important for real-time applications or scenarios where large amounts of data are generated that cannot be efficiently transmitted over the network to centralized data centers.
Edge clusters also provide advantages in terms of data privacy and security, as data can be processed and transmitted on-site without needing to leave the Edge network. However, operating an Edge cluster requires specialized infrastructure and robust network connectivity to ensure reliable communication with central clusters or cloud services.
Pros
Low latency: Edge clusters enable faster data processing by being positioned close to users or devices. This reduces latency and improves the performance of real-time applications.
Data security: Processing and storing data on-site in edge clusters can enhance data security and privacy. Sensitive data does not need to leave the edge network, reducing potential attack vectors.
Scalability: Edge clusters allow for resource scaling based on the requirements of the network edge. This enables efficient resource utilization and better adaptation to local demands.
Cons
Management complexity: Operating an edge cluster requires specialized infrastructure and a robust network connection. Managing and maintaining edge clusters can be complex, especially when they are distributed across multiple locations.
Dependency on network connections: Edge clusters heavily rely on reliable network connections to ensure efficient communication with central clusters or cloud services. Poor network connectivity can impact performance and availability.
Limited resources: Due to the limited capacity at edge locations, resource scalability may be constrained. This can be challenging when applications experience significant growth or need to process large volumes of data.
Air Gap Cluster
An Air Gap Cluster is a special type of cluster used in highly secure environments where complete isolation of the cluster from external networks is required. This is achieved through the physical separation of the cluster from public networks or the internet.
It's important to note that Air Gap Clusters are primarily used in security-critical environments where protection against external threats is of the highest priority. For most use cases, an Air Gap Cluster may not be necessary and can hinder connectivity and flexibility.
Pros:
Maximum Security: Air Gap Clusters provide an elevated level of security as they are completely isolated from external networks. This minimizes the risk of attacks, data breaches, or unauthorized access to sensitive information.
Protection against Threats: The air gap isolation makes it more difficult to introduce malware or other malicious programs into the cluster. This provides additional protection against threats originating from the network or the internet.
Compliance Requirements: Air Gap Clusters are often a requirement for organizations that need to adhere to strict security and compliance regulations. The physical isolation enables them to demonstrate compliance with these regulations.
Cons:
Limited Connectivity: Due to the isolation from the public network or the internet, connectivity to other systems or services may be restricted. Data exchange or integration with external systems can be challenging.
Deployment Complexity: Setting up an Air Gap Cluster requires careful planning and configuration. The physical isolation may involve additional effort in installing and wiring the infrastructure.
Constraints on Updates and Upgrades: Updating software, applying patches, or making configuration changes in an Air Gap Cluster can be complex since access to external resources or online repositories is restricted. It may require manual or offline mechanisms to perform these updates.
In Conclusiones
In this blog post, we have examined various Kubernetes cluster topologies and analyzed their advantages and disadvantages. Each cluster type offers unique characteristics and is suitable for different use cases and requirements.
The Seed cluster serves as a starting point for creating Kubernetes clusters, enabling easy scalability and management. Namespace clusters provide a flexible and isolated environment for different applications within the same cluster. Single node clusters can be a cost-effective option for development or small applications but have limited scalability and fault tolerance.
HA clusters offer high availability and automatic recovery in case of failures but require complex configuration. Federation clusters enable scaling across locations, increase redundancy, and improve performance but also introduce additional complexity in configuration.
Georedundant clusters provide increased fault tolerance and efficient scaling across geographical locations. Edge clusters offer low latency, data sovereignty, and support for offline scenarios but require specific infrastructure and can be challenging to maintain.
Air Gap clusters provide maximum security and compliance adherence but come with limitations in connectivity and require additional deployment and maintenance complexity.
When selecting a Kubernetes cluster type, it is important to consider specific requirements, security concerns, and scalability needs. It is recommended to carefully evaluate the pros and cons and choose the cluster type that best fits individual needs.
Overall, Kubernetes offers a diverse range of cluster topologies that allow businesses to operate their applications efficiently and at scale. By selecting and configuring the appropriate cluster type, organizations can benefit from a stable, secure, and highly available infrastructure.
Author: Martin Hafner
Read our latest Blogpost
