")

Kubernetes Probes
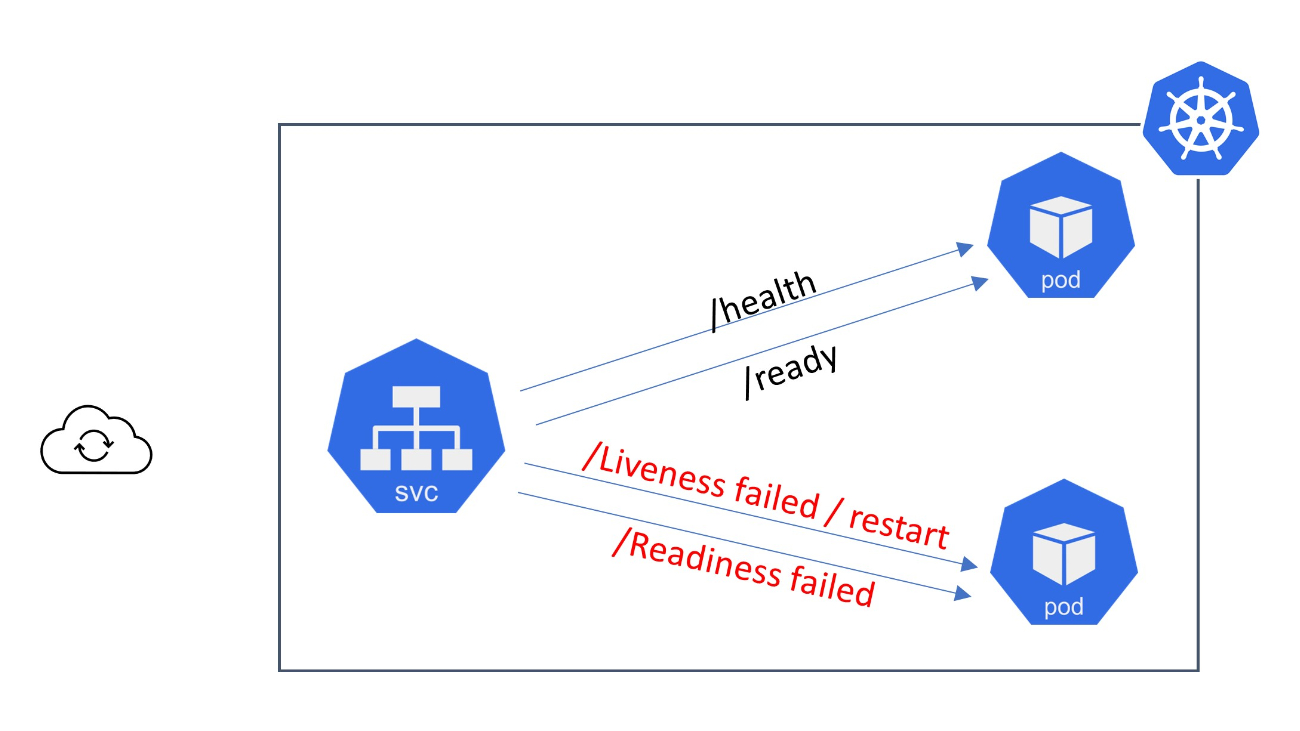
Innerhalb Kubernetes stellt ein Probe einen Mechanismus dar, bei welchem der Zustand als auch die Bereitschaft eines Containers oder einer in einem Pod laufenden Anwendung untersucht werden. Probes werden innerhalb der Pod-Spezifikationen definiert und erfahren regelmäßigen Einsatz, sodass die korrekte Funktionsweise der Anwendung gewährleistet werden kann. Kubernetes unterstützt drei Arten dieser Probes: Liveness-Probes, die Bereitschafts-Probes sowie Startup-Probes.
Liveness-Probe:
Ein Liveness-Probe behält die korrekte Ausführung eines Containers im Auge. Schlägt der Liveness Probe fehl, ordnet Kubernetes diesen Container als defekt ein und leitet angemessene Schritte ein, so etwa ein Neustart des Containers. Liveness-Probes sind unerlässlich für Anwendungen mit Runtime-Problemen oder Deadlock-Situationen.
Bereitschafts-Probe:
Ein Bereitschafts-Probe bestimmt, ob ein Container für die Aufnahme von Netzwerk-Traffic sowie die Verarbeitung von Anfragen ist. Damit wird sichergestellt, dass der Container den Initialisierungsprozess erfolgreich absolviert hat und infolgedessen dazu bereit ist, mit Anfragen zu verfahren. Schlägt der Bereitschafts-Probe fehl, entfernt Kubernetes die IP-Adresse von der Service-Liste der End-Points und leitet den Traffic an intakte Container weiter.
Startup-Probe:
Ein Startup-Probe wird für die Gewährleistung des Anwendungsstart innerhalb Ihres Containers genutzt. In erster Linie lohnt er sich dort, wo eine Anwendung länger für den Start braucht aber letztlich immer noch intakt werden kann. Im Gegensatz zu den vorangestellten Probes, verändert das Ergebnis des Startup-Probes nicht den Liveness- oder Bereitschafts-Status des Containers. Sobald der Startup-Probe gelingt, übernehmen die Bereitschafts- und Liveness-Probes entsprechend.
Für jeden Probe können zahlreiche Parameter definiert werden, wie etwa den Probe-Typ (HTTP, TCP, oder Exec), den Probe-Timeout, die Intervalle zwischen den Probe-Checks, die Anzahl an aufeinanderfolgenden Fehlschlägen vor der Einordnung in den „Gescheitert“-Status sowie die Erfolgskriterien.
Probes liefern Kubernetes die Möglichkeit, Container-Zustände sowie die -Bereitschaft automatisch zu verwalten und erlauben so eine höhere Widerstandsfähigkeit, Selbstheilung wie auch effizienteres Routing von Netzwerkverkehr in einem Cluster.
Gehen wir auf jeden der Probes im Detail ein:
Liveness-Probe:
Eine Liveness-Probe stellt fest, inwieweit ein Container noch läuft und korrekt funktioniert. Er prüft in regelmäßigen Abständen den Zustand der Anwendung bzw. Prozesses eines Containers und ergreift dann geeignete Maßnahmen, wenn der Probe fehlschlägt, wie z. B. den Neustart des Containers.
Im Folgenden werden die wichtigsten Aspekte von Kubernetes-Liveness-Probes erläutert:
Probe-Typen: Kubernetes unterstützt derzeit vier Arten von Liveness-Probes: HTTP, TCP, Exec und gRPC. Sie können also den Typ für Ihre Anwendung auswählen, der am ehesten Ihren Anforderungen entspricht.
- HTTP-Probe: Er sendet eine HTTP-GET-Anfrage an einen bestimmten Endpunkt mit der IP-Adresse und dem Port eines Containers. Wenn der Endpunkt einen erfolgreichen HTTP-Statuscode (2xx oder 3xx) zurückgibt, betrachtet der Probe den Container als betriebsbereit. Andernfalls wird davon ausgegangen, dass der Container defekt ist.
- TCP-Probe: Er versucht, eine TCP-Verbindung zu einem bestimmten Port des Containers zu öffnen. Wenn die Verbindung erfolgreich aufgebaut wird, gilt der Container als intakt. Andernfalls wird er als defekt eingestuft.
- Exec-Probe: Führt einen bestimmten Befehl innerhalb des Containers aus. Wird der Befehl mit einem Statuscode von Null beendet, gilt der Container als intakt. Andernfalls gilt er als defekt.
- gRPC-Probe: Seit Kubernetes Version 1.24 kann der gRPC-Handler so konfiguriert werden, dass er vom Kubelet für die Überprüfung der Anwendungslebensdauer verwendet wird. Um Checks zu konfigurieren, die gRPC verwenden, müssen Sie das Funktionsgatter GRPCContainerProbe aktivieren. Sie müssen den Port so konfigurieren, dass ein gRPC-Probe verwendet wird, außerdem müssen Sie den Dienst angeben, sofern der Zustands-Endpoint auf einem nicht standardmäßigen Dienst konfiguriert ist.
Timing und Parameter: Sie können verschiedene Parameter für Liveness-Probes konfigurieren, darunter:
- initialDelaySeconds: Die Verzögerung in Sekunden, bevor der erste Liveness-Probe ausgeführt wird. Dies gibt dem Container Zeit, um zu starten.
- periodSeconds: Das Zeitintervall zwischen aufeinanderfolgenden Liveness-Probes. Damit wird festgelegt, wie häufig die Prüfung durchgeführt werden soll.
- timeoutSeconds: Die maximale Zeitspanne, die jedem Liveness-Probe-Test eingeräumt wird, um diesen abzuschließen. Überschreitet der Probe diese Zeitspanne, wird der Versuch als gescheitert gewertet.
- failureThreshold: Die Anzahl der aufeinanderfolgenden, tolerierten Fehlschläge, die zulässig sind, bevor der Container als defekt betrachtet und die definierte Aktion (z. B. der Neustart des Containers) ausgelöst wird.
- successThreshold: Die Anzahl der aufeinanderfolgenden erfolgreichen Probes, welche erforderlich sind, um einen Container von einem defekten in einen intakten Zustand zu versetzen. Dieser Parameter hilft dabei, ein schnelles Hin- und Herspringen zwischen defekten und intakten Zuständen zu verhindern.
Aktionen bei Fehlschlag des Probe: Wenn ein Liveness-Probe fehlschlägt, führt Kubernetes die angegebene Aktion basierend auf der Neustartrichtlinie des Pods aus:
- Sofern für den Pod eine RestartPolicy auf "Always" gesetzt ist, startet Kubernetes den Container neu.
- Wenn die RestartPolicy des Pods jedoch auf "OnFailure" oder "Never" gesetzt ist, startet Kubernetes den Container nicht neu aber der fehlgeschlagene Probe wirkt sich auf den allgemeinen Gesundheitsstatus des Pods aus.
Liveness-Probes sind entscheidend für die Erkennung und Behebung von Problemen, welche während der Laufzeit auftreten, wie etwa Anwendungsabstürze oder Deadlock-Situationen. Durch die regelmäßige Überprüfung des Zustands von Containern kann Kubernetes automatisch mit defekten Containern verfahren und die allgemeine Verfügbarkeit und Stabilität Ihrer Anwendungen gewährleisten.
Das folgende Beispiel zeigt, wie Sie einen Liveness-Probe in einer Kubernetes-Pod-Spezifikation mithilfe einer HTTP-Probe definieren können:
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-container
image: my-image:latest
ports:
- containerPort: 8080
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
failureThreshold: 3
timeoutSeconds: 5
In diesem Beispiel haben wir einen Pod mit einem einzelnen Container namens "my-container". Der Container verwendet das Image "my-image:latest" und stellt Port 8080 zur Verfügung. Für den Container wurde ein Liveness-Probe definiert. Der Liveness-Probe ist als HTTP-Probe konfiguriert, welcher den Endpunkt /health an Port 8080 des Containers überprüft. Wenn der Endpunkt einen erfolgreichen HTTP-Statuscode (2xx oder 3xx) zurückgibt, betrachtet der Probe den Container als intakt. Andernfalls geht er davon aus, dass der Container defekt ist.
Der Liveness-Probe startet nach einer anfänglichen Verzögerung von 15 Sekunden und wird alle 10 Sekunden neugestartet. Der Probe erlaubt maximal 3 aufeinanderfolgende Ausfälle, bevor der Container als defekt eingestuft wird. Jeder Probe durchläuft einen Timeout von 5 Sekunden, sodass der Probe als fehlgeschlagen gilt, wenn er nicht innerhalb von 5 Sekunden eine Antwort erhält.
Wenn der Liveness-Probe fehlschlägt, führt Kubernetes die angegebene Aktion auf der Grundlage der Neustartrichtlinie des Pods aus. Wenn die RestartPolicy des Pods beispielsweise auf "Always" gesetzt ist, startet Kubernetes den Container entsprechend neu.
Bitte beachten Sie, dass Sie den Pfad, den Port, das Timing und andere Parameter entsprechend den Anforderungen und der Einrichtung Ihrer jeweiligen Anwendung anpassen müssen.
Bereitschafts-Probe:
Ein Bereitschafts-Probe ist ein Mechanismus, mit welchem ermittelt werden kann, ob ein Container bereit ist, Netzwerkverkehr zu empfangen und Anfragen zu bedienen. Er stellt sicher, dass der Container seinen Initialisierungsprozess abgeschlossen hat und bereit ist, eingehende Anfragen zu bearbeiten. Bereitschafts-Probes spielen eine entscheidende Rolle bei der reibungslosen Weiterleitung des Datenverkehrs und der Lastverteilung innerhalb eines Kubernetes-Clusters.
Hier sind die wichtigsten Aspekte des Bereitschafts-Probes:
Probe-Typen: Ähnlich wie bei den Liveness-Probes unterstützt Kubernetes drei Arten von Bereitschafts-Probes: HTTP, TCP und Exec. Sie können also auch hier den Typ wählen, welcher am ehesten den Anforderungen Ihrer Anwendung entspricht.
- HTTP-Probe: Er sendet eine HTTP-GET-Anfrage an einen bestimmten Endpunkt mit der IP-Adresse und dem Port eines Containers. Wenn der Endpunkt einen erfolgreichen HTTP-Statuscode (2xx oder 3xx) zurückgibt, betrachtet der Probe den Container als intakt. Andernfalls geht er davon aus, dass der Container defekt ist.
- TCP-Probe: Er versucht, eine TCP-Verbindung zu einem bestimmten Port des Containers zu öffnen. Sofern die Verbindung erfolgreich aufgebaut wird, gilt der Container als intakt. Andernfalls gilt er als defekt.
- Exec-Probe: Führt einen bestimmten Befehl innerhalb des Containers aus. Wenn der Befehl mit einem Statuscode von Null beendet wird, gilt der Container als intakt. Andernfalls gilt er als defekt.
Timing und Parameter: Sie können verschiedene Parameter für Bereitschafts-Probes konfigurieren, darunter:
- initialDelaySeconds: Die Verzögerung in Sekunden, bevor der erste Bereitschafts-Probe initialisiert wird. Dies gibt dem Container Zeit, um zu starten und seinen Initialisierungsprozess abzuschließen.
- periodSeconds: Das Zeitintervall zwischen aufeinanderfolgenden Bereitschafts-Probes. Damit wird festgelegt, wie häufig die Probes gestartet werden sollen.
- timeoutSeconds: Die maximale Zeitspanne, die jedem Bereitschafts-Probe zum Abschluss eingeräumt wird. Überschreitet der Bereitschafts-Probe diese Zeitspanne, wird der Versuch als gescheitert betrachtet.
- failureThreshold: Die Anzahl der aufeinanderfolgenden Fehlversuche, die zulässig sind, bevor der Container als defekt betrachtet wird. Wenn die Fehlerschwelle erreicht ist, wird die IP-Adresse des Containers aus der Liste der Endpunkte des Dienstes entfernt und resultiert letztlich in die Umleitung des Verkehrs vom defekten Container hinweg.
Aktionen bei Fehlschlag des Probes: Wenn ein Bereitschafts-Probe fehlschlägt, stuft Kubernetes den Container als nicht bereit ein und ergreift je nach Konfiguration des Pods entsprechende Maßnahmen:
- Ist ein Pod Teil eines Dienstes und sein Bereitschafts-Probe schlägt fehl, entfernt Kubernetes die IP-Adresse des Pods aus der Liste der Endpunkte des Dienstes. Dadurch wird sichergestellt, dass der Verkehr nicht zum Container geleitet wird, bis dieser wieder bereit ist.
- Sofern der Bereitschafts-Probe fehlschlägt und die RestartPolicy des Pods auf "Always" gesetzt ist, startet Kubernetes den Container nicht automatisch neu. Stattdessen wird gewartet, bis der Container auf Grundlage der definierten Probe-Konfiguration bereit ist.
Readiness-Probes sind wichtig, um sicherzustellen, dass nur intakte und vollständig initialisierte Container Datenverkehr erhalten, um Unterbrechungen zu minimieren und eine reibungslose Service-Erkennung sowie Lastverteilung innerhalb des Kubernetes-Clusters zu ermöglichen.
Das folgende Beispiel zeigt, wie Sie einen Bereitschafts-Probe in einer Kubernetes-Pod-Spezifikation mithilfe eines HTTP-Probe definieren können:
In diesem Beispiel haben wir einen Pod mit einem einzelnen Container namens "my-container". Der Container verwendet das Image "my-image:latest" und stellt Port 8080 zur Verfügung. Für den Container ist ein Bereitschafts-Probe definiert. Dieser ist als HTTP-Probe konfiguriert, welcher den Endpunkt /health an Port 8080 des Containers überprüft. Wenn der Endpunkt einen erfolgreichen HTTP-Statuscode (2xx oder 3xx) zurückgibt, betrachtet der Probe den Container als intakt. Andernfalls geht er davon aus, dass der Container nicht betriebsbereit ist.
Der Bereitschafts-Probe initialisiert nach einer anfänglichen Verzögerung von 10 Sekunden und wird alle 5 Sekunden neugestartet. Die Prüfung lässt maximal 3 aufeinanderfolgende Fehler zu, bevor der Container als nicht bereit betrachtet wird. Jeder Probe hat einen Timeout von 2 Sekunden, was bedeutet, dass der Probe als fehlgeschlagen gilt, falls er nicht innerhalb von diesen 2 Sekunden eine Antwort erhält.
Wenn der Bereitschafts-Probe fehlschlägt und der Pod Teil eines Dienstes ist, entfernt Kubernetes die IP-Adresse des Pods aus der Liste der Endpunkte des Dienstes. Dadurch wird sichergestellt, dass kein Datenverkehr an den Container geleitet wird, bis er wieder bereit ist.
Bitte beachten Sie, dass Sie den Pfad, den Port, das Timing und andere Parameter entsprechend den Anforderungen und der Einrichtung Ihrer spezifischen Anwendung anpassen müssen.
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-container
image: my-image:latest
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3Startup-Probe:
Der Startup-Probe ist eine Probe-Art, welche in Kubernetes Version 1.16 eingeführt wurde, um Szenarien zu behandeln, in welchen Container eine längere Zeit brauchen, um zu starten, aber schließlich doch intakt werden können. Dieser ist besonders nützlich für Anwendungen, die einen zeitintensiven Initialisierungsprozess benötigen oder über Abhängigkeiten verfügen, welche erst vollständig hergestellt werden müssen, bevor die Anwendung als bereit angesehen wird.
Im Gegensatz zu Liveness- und Bereitschafts-Probes hat das Ergebnis eines Startup-Probes keinen direkten Einfluss auf den Readiness- oder Liveness-Status des Containers. Der Zweck des Startup-Probe ist es, festzustellen, ob die Container-Anwendung erfolgreich gestartet wurde und damit einhergehend signalisiert, dass sie sich auf dem Weg zum intakten Zustand befindet. Der Startup-Probe wird nur einmal gestartet. Dies geschieht, sobald ein Pod geplant wird.
Der Startup-Probe hat eine höhere Priorität als die beiden anderen Probe-Typen. Bis der Startup-Probe erfolgreich ist, sind alle anderen Probes deaktiviert.
Hier sind die wichtigsten Merkmale eines Startup-Probes:
Probe-Typ: Wie andere Probes in Kubernetes unterstützt auch der Startup-Probe drei Typen: HTTP, TCP und Exec. Sie können also auch hier den Typ wählen, der am besten für den Startvorgang Ihrer Anwendung geeignet ist.
Timing und Parameter: Ähnlich wie bei den Liveness- und Bereitschafts-Probes können Sie verschiedene Parameter für die Startup-Probe konfigurieren, darunter die Zeitüberschreitung des Probe, das Intervall zwischen den Probe-Checks, die Anzahl der aufeinanderfolgenden Fehler, bevor der Probe als fehlgeschlagen betrachtet wird, und die Erfolgskriterien.
Transition to Liveness and Readiness: Once the startup probe succeeds, the liveness and readiness probes take over. This means that after the container passes the startup probe, its readiness and liveness status will be evaluated based on the respective configurations for those probes.
Übergang zu Liveness und Readiness: Sobald der Startup-Probe erfolgreich ist, übernehmen die Liveness- und Bereitschafts-Probes. Das heißt, nachdem der Container den Startup-Probe akzeptiert hat, werden sein Bereitschafts- bzw. Liveness-Status auf der Grundlage der jeweiligen Konfigurationen für diese Probes bewertet.
Durch die Einführung des Startup-Probe bietet Kubernetes eine Möglichkeit, zwischen Containern zu unterscheiden, die sich noch in der Initialisierung befinden, und solchen, bei denen ein Laufzeitfehler aufgetreten ist. Damit kann Kubernetes einen Container erst dann als defekt und betriebsbereit einstufen, wenn er eine realistische Chance hatte, erfolgreich zu starten. Dies hilft dabei, sogenannte False-Negatives und unnötige Neustarts von Containern zu vermeiden, welche lediglich mehr Zeit benötigen, um ihren Initialisierungsprozess abzuschließen.
Das folgende Beispiel zeigt, wie Sie in einer Kubernetes-Pod-Spezifikation mithilfe eines HTTP-Probes einen Startup-Probe definieren können:
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-container
image: my-image:latest
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
startupProbe:
httpGet:
path: /startup
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
failureThreshold: 30
In diesem Beispiel haben wir einen Pod mit einem einzelnen Container namens "my-container". Der Container verwendet das Image "my-image:latest" und stellt Port 8080 zur Verfügung. Der Pod hat sowohl einen Bereitschafts-Probe als auch einen Startup-Probe definiert. Der Bereitschafts-Probe prüft den Endpunkt /health an Port 8080, um festzustellen, ob der Container bereit ist, Datenverkehr zu empfangen. Er initialisiert nach einer anfänglichen Verzögerung von 10 Sekunden und wird alle 5 Sekunden neugestartet.
Der Startup-Probe hingegen prüft den Endpunkt /startup an Port 8080, um festzustellen, ob die Anwendung des Containers erfolgreich gestartet wurde. Dieser startet nach einer anfänglichen Verzögerung von 5 Sekunden und wird alle 10 Sekunden neugestartet. Der Startup-Probe lässt maximal 30 aufeinanderfolgende Fehlversuche zu, bevor er als fehlgeschlagen betrachtet wird.
Sobald der Startup-Probe erfolgreich war, wird die Bereitschaft des Containers auf der Grundlage der Konfiguration des Bereitschafts-Probe bewertet.
Bitte beachten Sie, dass Sie die Pfade, Ports und anderen Parameter entsprechend den Anforderungen und der Konfiguration Ihrer Anwendung anpassen müssen.
Hier sehen Sie ein paar der potentiellen Probleme mit Kubernetes-Probes:
- Falsch konfigurierte Probes: Ein häufiges Problem ist die Fehlkonfiguration der Probes, z. B. die Angabe von falschen Endpunkten, Ports oder Pfaden. Dies kann zu sogenannten False-Positives bzw. den schon vorhin erwähnten False-Negatives führen, sodass Container fälschlicherweise als defekt oder, noch schlimmer, intakt eingestuft werden.
- Überschreitung des Zeitlimits: Wenn die Zeitüberschreitung für einen Probe zu niedrig eingestellt ist, kann dies zu falschen, unnötigen Fehlermeldungen führen. Wenn der Container aufgrund hoher Lasten oder komplexer Initialisierungsprozesse länger braucht, um zu reagieren, kann der Probe eine Zeitüberschreitung verursachen und den Container als defekt markieren, was zu unnötigen Neustarts führt.
- Unempfängliche oder langsame Anwendungen: Probes sind auf die Reaktionsfähigkeit der Anwendung oder des Prozesses innerhalb des Containers angewiesen. Wenn die Anwendung aufgrund von Fehlern, Leistungsproblemen oder Ressourcenbeschränkungen nicht oder nur langsam reagiert, kann dies zu False-Negatives und somit einer Fehleinschätzung des Containerzustands führen.
- Ressourcenbeschränkungen: In Fällen, in welchen Probes Container zusätzlich belasten, z.B. durch HTTP-Anfragen oder die Ausführung von Befehlen, kann dies Ressourcen verbrauchen und im schlimmsten Fall die Leistung der Anwendung beeinträchtigen. Dem können Verzögerungen bei der Reaktionsfähigkeit der Anwendung oder eine erhöhte Ressourcenauslastung folgen.
- Timing-Probleme: In bestimmten Szenarien kann das Timing eine Herausforderung darstellen. Wenn zum Beispiel die anfängliche Verzögerung für einen Bereitschafts-Probe zu kurz ist, kann die Prüfung beginnen, bevor die Anwendung des Containers ihre Initialisierung abgeschlossen hat. Dies kann zu False-Negatives führen und so verhindern, dass der Container für's Erste Datenverkehr erhält.
- Störung des Container-Startvorgangs: Wenn ein Liveness- oder Bereitschafts-Probe zu aggressiv ist, kann dieser den Startprozess eines Containers unterbrechen. Wenn der Probe zum Beispiel zu früh startet und während der Initialisierungsphase Neustarts auslöst, kann er so verhindern, dass der Container seine Einrichtung ordnungsgemäß abschließt.
- Kubernetes-Probes sind von Neustart-Richtlinien betroffen. Es ist wichtig zu wissen, dass Container-Neustart-Policies via Probes angewendet werden. Das gilt nur sofern Ihre Container auf restartPolicy: "Always" (der Standard) oder restartPolicy: "OnFailure" gestellt sind, damit Kubernetes sie nach einer fehlgeschlagenen Prüfung überhaupt neu starten kann.
Daher sollten Sie die Never-Richtlinie verwenden, denn dann verbleibt der Container im fehlgeschlagenen Zustand.
- Startup-Verzögerung: Wenn die anfängliche Verzögerung für einen Probe zu kurz eingestellt ist, kann er beginnen, bevor der Container/die Anwendung seinen/ihren Initialisierungsprozess abgeschlossen hat. Dies kann zu False-Negatives führen, da der Container möglicherweise nicht vollständig bereit ist, Anfragen zu bearbeiten oder auf Probes zu reagieren.
Es ist wichtig, Probes sorgfältig zu entwerfen und zu konfigurieren, basierend auf den Eigenschaften und Anforderungen Ihrer spezifischen Anwendung. Regelmäßige Überwachung, Fehlerbehebung und Abstimmung der Probe-Einstellungen können dazu beitragen, etwaige Probleme zu lösen und die genaue Erkennung des Zustands als auch die Bereitschaft von Containern innerhalb eines Kubernetes-Clusters sicherzustellen.
Wichtig zu wissen, ist dass die Probes via Kubelet kontrolliert werden.
Ein Nachteil der Liveness-Probe ist, dass die Reaktionsfähigkeit eines Dienstes nicht überprüft werden kann.
Weiterhin muss die Veränderung der Dynamik berücksichtigt werden. Diese kann sich im Laufe der Zeit ändern.
Ein Beispiel hierfür: Reagiert ein Container aufgrund eines kurzen Lastanstiegs etwas später, kann es zu einem Neustart des Containers kommen, wenn Sie die Timeout-Zeit des Liveness-Probe zu kurz einstellen. Ein solcher Neustart kann dazu führen, dass auch andere Pods Probleme bekommen, da es dann zu weiteren Ausfällen der Liveness-Probe kommen kann.
Wenn Sie sicherstellen wollen, dass die Container zuverlässig gestartet werden, sollten Sie die Option "intitialDelaySeconds" eher konservativ setzen.
Ein weiterer Punkt, der bei Probes zu beachten ist, ist die Netzwerklatenz. Sie müssen bei der Einstellung der Timeouts vorsichtig sein.
Wie können Sie die Probes überprüfen?
- Für den Bereitschafts-Probe können Sie dies mit „
kubectl get po“ sehen. Sie können dies mit einer Beschreibung des Pods überprüfen: „kubectl describe pod <pod name>“ - kube-state-metrics: Wenn Sie Kube-State-Metrics in Ihrem Cluster installiert haben, können Sie dies verwenden, um den Status von Probes abzufragen.
- Überwachungs- und Protokollierungstools: Sie können Überwachungs- und Protokollierungstools wie Prometheus, Grafana oder ELK Stack (Elasticsearch, Logstash, Kibana) verwenden, um Probe-bezogene Metriken und Protokolle zu sammeln als auch visualisieren.
- Container-Runtime-Interface (CRI) Tools: Wenn Sie die Probe-Ergebnisse auf der Container-Laufzeitebene überprüfen müssen, können Sie CRI-Tools verwenden, die speziell für Ihre Container-Laufzeitumgebung geeignet sind, wie z. B. docker stats für Docker oder crictl für containerd.
Für diejenigen, welche nach noch mehr Informationen dürsten, können wir Sie auf diese Kubernetes-Dokumentation verweisen:
Author: Ralf Menti
