")

Mit dem Übergang zu einer modernen digitalen Landschaft nehmen die erzeugten Datenströme von Anwendungen und Infrastrukturen exponentiell zu. Um diese enormen Datenmengen zu entschlüsseln, sind Tools wie Grafana und Prometheus unerlässlich geworden. Sie sind nicht nur einfache Zahlen, sondern geben Aufschluss über den Zustand, die Leistung und die Feinheiten von Systemen.
In diesem Blog-Beitrag wird die Funktionsweise dieser Tools näher erläutert und überdies werden einige großartige Funktionen, Dashboards und Warnmechanismen vorgestellt.
Grafana und Prometheus verstehen
Prometheus: Ein Open-Source-Toolkit zur Systemüberwachung und Alarmierung, dessen Kernfunktionalität darin besteht, in bestimmten Intervallen Metriken von konfigurierten Zielen zu sammeln, Regelausdrücke innerhalb seiner domänenspezifischen Sprache (PromQL) auszuwerten, Ergebnisse anzuzeigen und Alarme auszulösen, sofern bestimmte Bedingungen erfüllt sind.
Grafana: Eine Open-Source-Plattform für die Überwachung und Überschaubarkeit. Sie lässt sich in Prometheus integrieren und ermöglicht es Benutzern, die gesammelten Metriken in umfassenden Dashboards zu visualisieren. Diese Open-Source-Plattform ist für ihre beeindruckenden Visualisierungen bekannt und verwandelt die verworrenen Metrikdaten Prometheus' in aufschlussreiche Grafiken und Warnmeldungen, welche die Rohdaten für den menschlichen Aufseher besser verdaulich sowie umsetzbar machen.
Zusammenspiel zwischen Grafana und Prometheus
Während Prometheus sorgfältig Metriken sammelt und speichert, zieht Grafana jene Daten heran und bietet eine Schnittstelle zur Erstellung bezaubernder Dashboards. Die Kommunikation erfolgt über HTTP mit der Prometheus-API, sodass Grafana die Daten abrufen, anhäufen und visualisieren kann.
Beeindruckende Funktionen und Einsichten:
-
Ad-Hoc-Filter: Grafana ermöglicht On-the-fly-Abfragen, so dass Sie bestimmte Metriken je nach aktuellem Bedarf extrahieren können, ohne die Notwendigkeit zum Anpassen der ursprünglichen Dashboard-Einstellungen.
-
PromQL: Die native Abfragesprache von Prometheus ermöglicht eine komplexe Abfrage von Daten. Ganz gleich, ob Sie die Anwendungsleistung, die Ressourcennutzung oder Systemanomalien einsehen möchten, PromQL bietet solide Mittel für Datenmanipulation.
-
Dynamische Warnungen: Prometheus kann so konfiguriert werden, dass Alarme auf der Grundlage komplexer Bedingungen aktiviert werden. Diese Alarme werden in Grafana verbildlicht und geben somit einen klaren Hinweis auf den Systemzustand und damit mögliche einhergehende Probleme.
-
Annotationen in Grafana: Sie können Ihre Diagramme mit Ereignissen wie Deployments oder Ausfällen markieren. Dies hilft bei der Zusammenhangserstellung von metrischen Anomalien mit spezifischen Ereignissen innerhalb Ihrer Infrastruktur.
-
Templates und Variablen: Grafana-Dashboards sind dynamisch, sprich Sie können den Kontext wechseln, wie etwa einen angezeigten Server oder eine Anwendung ändern, ohne den Dashboard-Code ändern zu müssen. Diese Anpassungsfähigkeit wird durch den Einsatz von Variablen erreicht.
Effektive Dashboards schaffen
Dashboards sollten stets informativ, doch nicht überwältigend sein. Dafür sehen Sie hier eine mögliche Struktur:
- Übersicht Dashboard: High-Level-Metriken, die eine Momentaufnahme über den Zustand des Systems liefern. Beispiele: CPU-Auslastung, Speichernutzung, HTTP-Anforderungsrate und Fehlerrate.
- Node-Exporter-Dashboard: Bietet einen umfassenden Überblick über die Metriken Ihres Systems - CPU-Auslastung, Speicher, Netzwerkstatistiken und vieles mehr. Dies ist gerade nützlich für Systemadministratoren zur Überwachung des Serverzustands.
- Kubernetes-Cluster-Monitoring: Sofern Sie Kubernetes verwenden, bietet Grafana Dashboards zur Überwachung des Clusterzustands, der Ressourcennutzung von etwa Pods, Services als auch Nodes sowie der Anwendungsmetriken.
- Detaillierte Service-Dashboards: Diese haben ihren Fokus auf bestimmten Diensten. Wenn Sie zum Beispiel eine Datenbank besitzen, würden Sie Metriken wie Abfragerate, Latenz, aktive Verbindungen und Cache-Trefferrate haben.
- Warnhinweis-Dashboards: Konzentrieren sich ausschließlich auf ausgelöste Alarme und deren Details.
- Historischer Kontext: Nutzen Sie die Grafana-Zeitreisefunktion. Stellen Sie historische Daten gemeinsam zu Echtzeitmetriken an, um Trends und Anomalien zu verstehen.
Example Dashboards
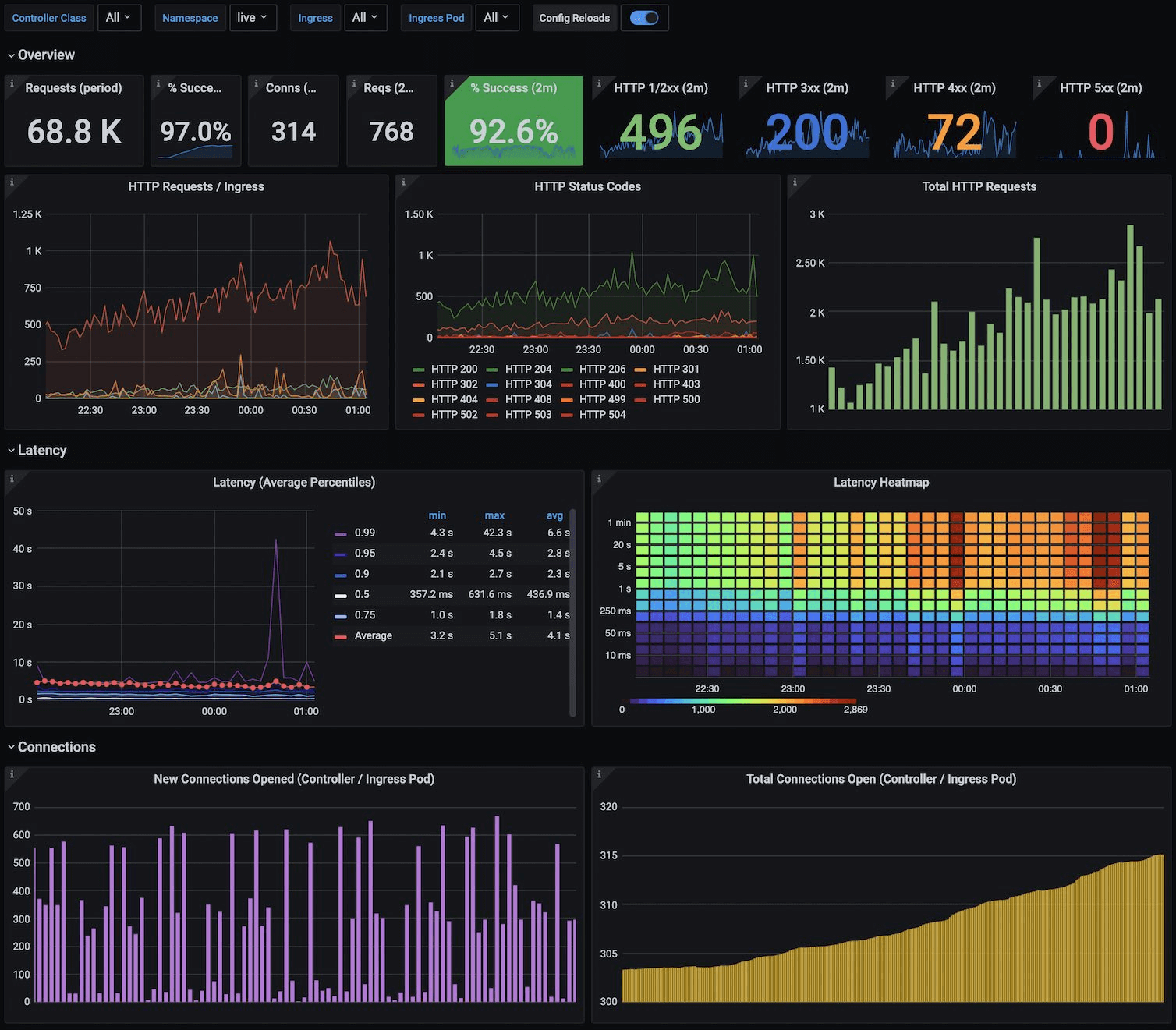
NGINX Ingress Controller Dashboard
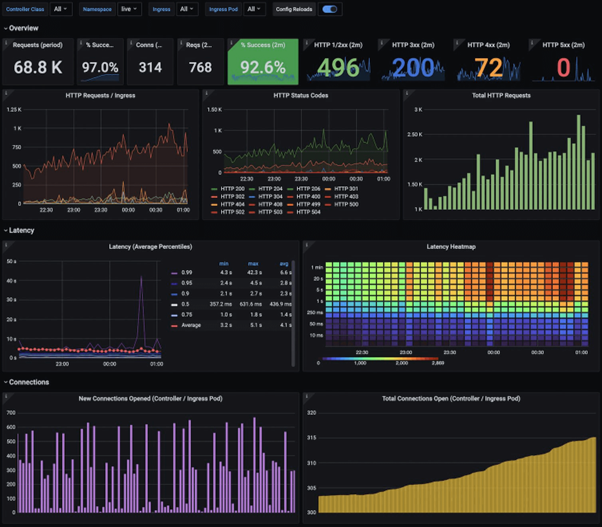
https://grafana.com/static/assets/img/blog/kubernetes_nginx_dash.png
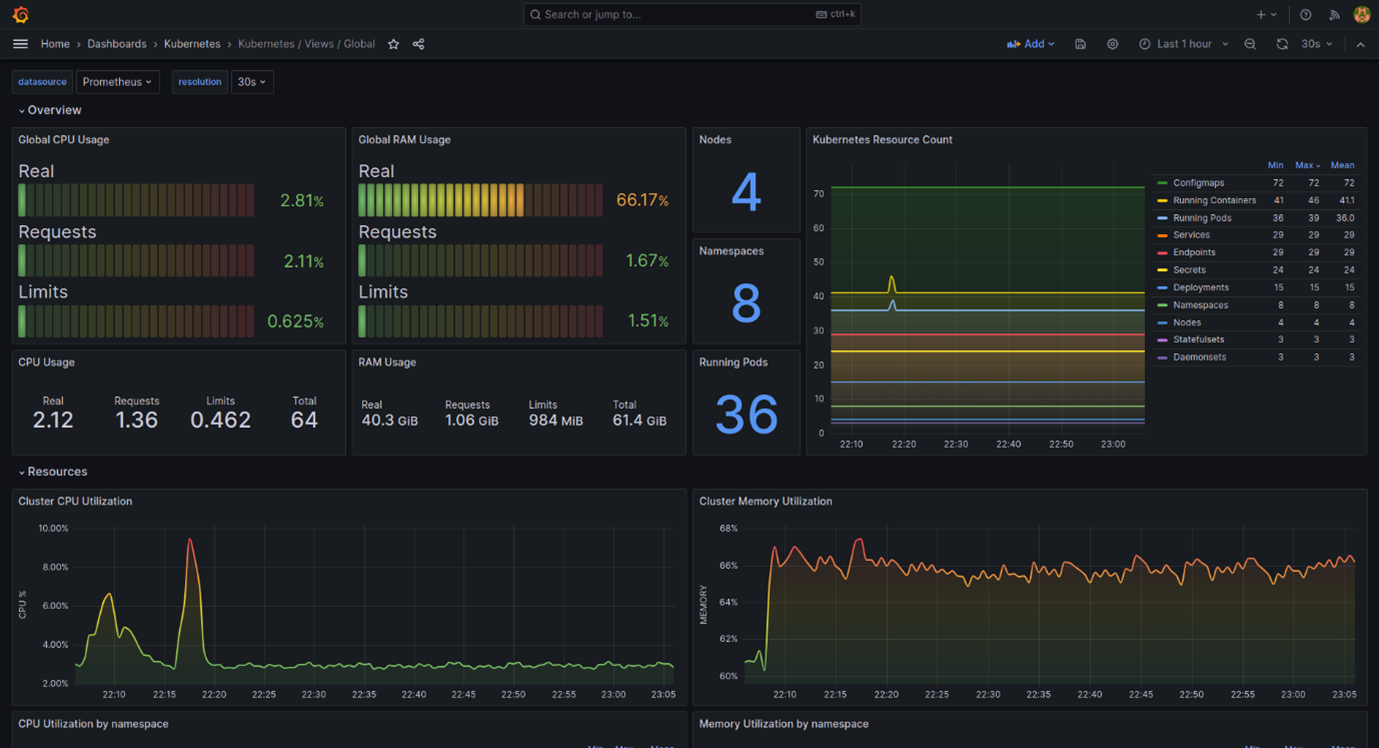
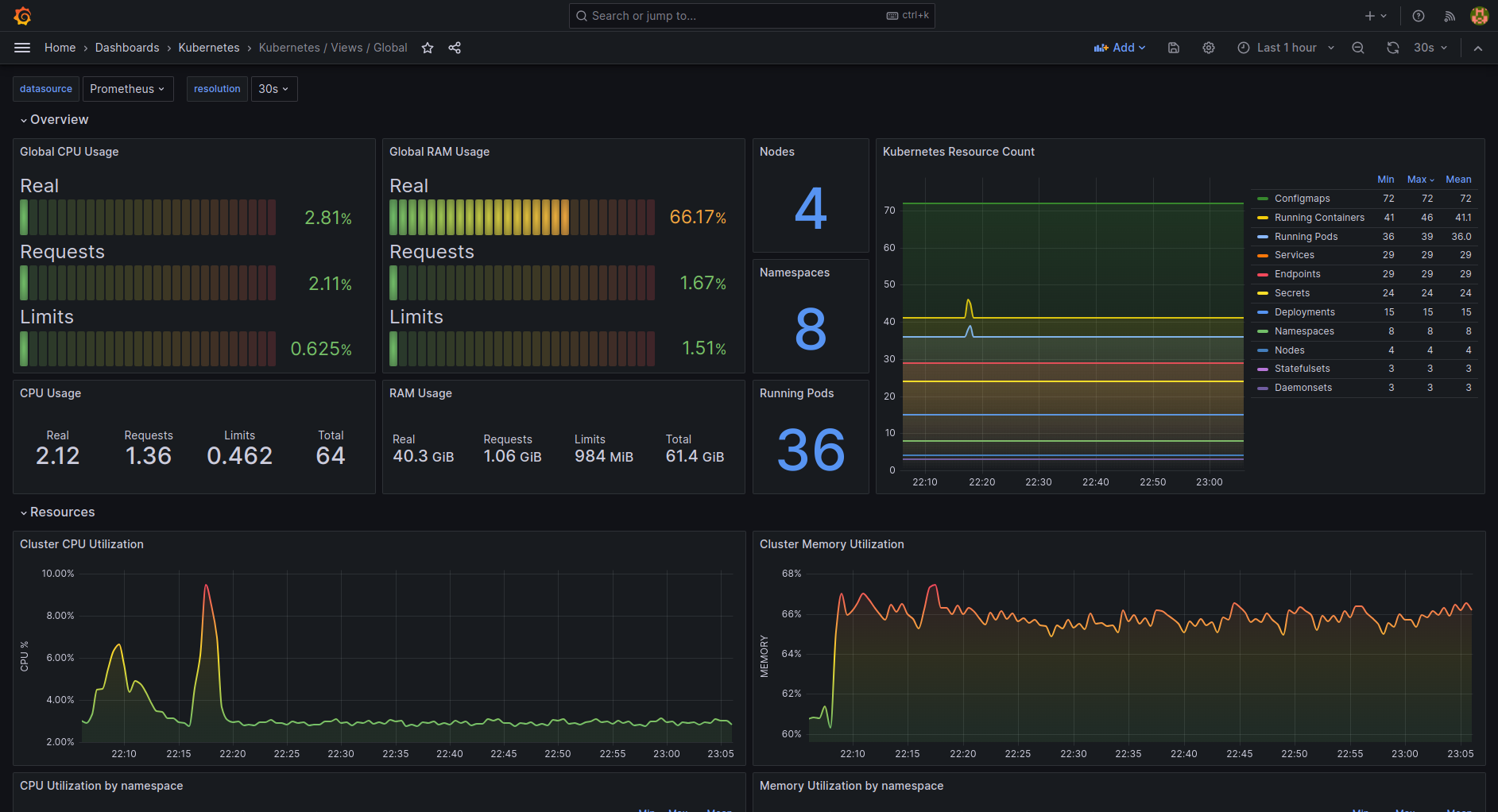
Kubernetes Global Dashboard
Kubernetes Pods Dashboard
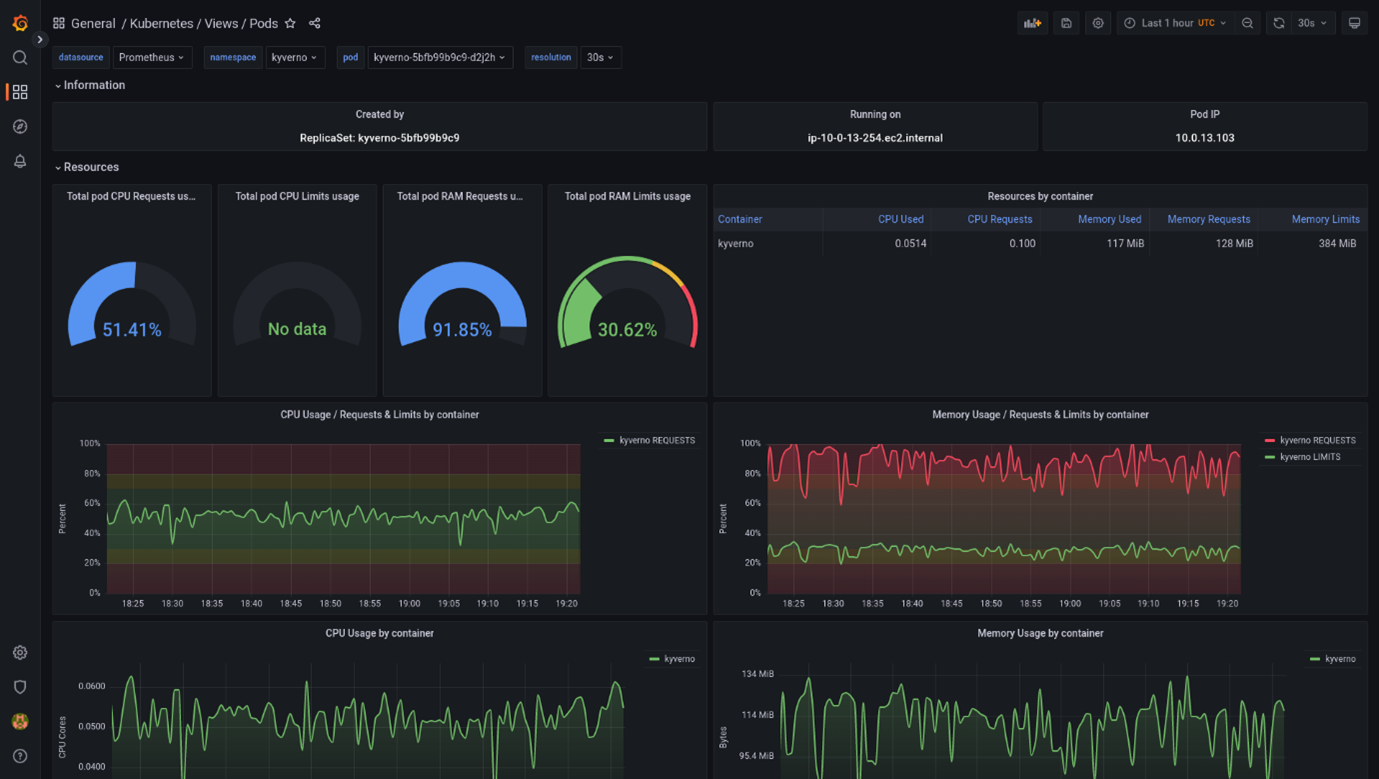
https://grafana.com/api/dashboards/15760/images/12599/image
Alarm-Mechanismen in Grafana:
Grafana erlaubt das Erstellen von Alarmen, welche Sie beim Eintreffen der vorgegebenen Bedingungen informieren. Hier sehen Sie ein einfaches Beispiel:
- Schritt: Öffnen Sie das Dashboard-Panel und fügen Sie einen Alarm hinzu.
- Schritt: Klicken Sie auf den „Alert“-Tab und wählen Sie „Create Alert“.
- Schritt: Definieren Sie die Alarmbedingungen. Sie könnten zum Beispiel einen Alarm definieren, welcher bei 80% CPU-Auslastung über einen Zeitraum von mehr als fünf Minuten liegt.
- Schritt: Entscheiden Sie das Medium Ihres Alarms wie etwa E-Mail, Slack, Webhook, etc.
- Schritt: Speichern Sie Ihr Dashboard ab.
Sofern die vorgegebenen Bedingungen eintreten, tritt Grafana den Alarm in Kraft und sendet einen Alarm an das von Ihnen gewählte Medium.
Diese Alarme können in Grafana visualisiert werden, aber noch wichtiger ist, dass sie an verschiedene Alertmanager-Setups weitergeleitet werden können. Ein Alertmanager kann mit Kommunikationsplattformen wie E-Mail, Microsoft Teams, Slack oder PagerDuty integriert werden, und stellt so sicher, dass die richtigen Personen umgehend informiert werden.
Alarm-Mechanismen in Prometheus
Prometheus geht über das einfache Sammeln von Daten hinaus; Auch bietet es einen robusten Alarmmechanismus. So können Sie einen Alarm einstellen:
Alarm-Regeln definieren: Erstellen Sie eine Yaml-Datei mit Ihren Alarm-Konfigurationen. Um zum Beispiel bei hoher Speichernutzung zu warnen, sehen Sie folgendes:
<YAML START>
groups:
- name: example
rules:
- alert: HighMemoryUsage
expr: (node_memory_MemTotal_bytes - node_memory_MemFree_bytes) / node_memory_MemTotal_bytes > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "High memory usage detected on {{ $labels.instance }}"
<YAML END>
Prometheus neuladen: Nach dem Definieren Ihrer Alarme müssen Sie Prometheus neustarten, um diese anzuwenden.
Integration mit Hilfe des Alarm-Managers: Prometheus liefert Alarme an den Alarm-Manager weiter, welcher sich dann deren Verwaltung, darunter das Stummschalten, die Hemmung, die Anhäufing und das Versenden von Benachrichtigungen via E-Mail, Slack oder anderen.
Integrating Alerts with Microsoft Teams
Obwohl es durchaus großartig ist, Alarme in Prometheus sowie visuelle Hinweise in Grafana zu haben, müssen diese Alarme manchmal an die Kommunikationsplattform Ihres Teams weitergeleitet werden. Microsoft Teams als eines der beliebtesten Kollaborationstools kann über den Alertmanager direkt in Prometheus-Alerts integriert werden.
Beispiel Alarm-Konfigurationen für Microsoft Teams
Hier sehen Sie ein Beispiel einer Alarm-Regelung in Prometheus, welche bei hoher Speicherauslastung in Kraft tritt.
<YAML START>
groups:
- name: teams-example
rules:
- alert: HighMemoryUsage
expr: (node_memory_MemTotal_bytes - node_memory_MemFree_bytes) / node_memory_MemTotal_bytes > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "High memory usage on {{ $labels.instance }}"
description: "{{ $labels.instance }} memory usage is above 80% (current value: {{ $value }})"
<YAML END>
Sobald die Alarm-Regelung in Prometheus angewendet ist, besteht der nächste Schritt im Konfigurieren des Alertmanagers, sodass die Alarme auch an Microsoft Teams geleitet werden.
Ihrer Alertmanager-Konfiguration sollte ähnlich wie hier aussehen:
<YAML START>
route:
group_by: ['alertname', 'cluster', 'service']
receiver: 'msteams-notifications'
receivers:
- name: 'msteams-notifications'
msteams_configs:
- webhook_url: 'YOUR_MICROSOFT_TEAMS_WEBHOOK_URL'
Replace YOUR_MICROSOFT_TEAMS_WEBHOOK_URL with your actual Teams Incoming Webhook URL.
<YAML END>
Wie funktioniert’s?
Einrichten von Microsoft Teams: Zunächst müssen Sie einen "Eingehenden Webhook" für Ihren Microsoft Teams-Kanal einrichten. Dadurch erhalten Sie eine Webhook-URL, welche für Push-Benachrichtigungen an diesen speziellen Kanal verwendet wird.
Alertmanager konfigurieren: Wenn Prometheus eine Benachrichtigung auslöst, die den definierten Kriterien entspricht (in unserem Fall: hohe Speichernutzung), leitet der Alertmanager diese Benachrichtigung an den angegebenen Microsoft Teams-Kanal weiter.
Empfangen von Alerts: Sobald alles eingerichtet ist, erhält Ihr Team Warnungen direkt im Microsoft Teams-Kanal, sodass eine schnelle Reaktion auf mögliche Probleme gewährleistet ist.
Durch die Integration von Prometheus-Alerts über Microsoft Teams stellen Sie sicher, dass kritische Alerts nicht nur für jemanden sichtbar sind, der Grafana-Dashboards überwacht, sondern aktiv an Ihr Team weitergeleitet werden, um schnelles Handeln und Zusammenarbeit zu fördern.
Bewährte Methoden
- Machen Sie es sich nicht unnötig schwer: Es ist verlockend, einem Dashboard zahlreiche Kennzahlen hinzuzufügen, doch steht Klarheit oft über Komplexität. Beginnen Sie mit den wichtigsten Metriken und erweitern Sie sie bei Bedarf.
- Verwenden Sie prägnante Bezeichnungen: Stellen Sie sicher, dass Ihre Metriken und Panels aussagekräftig benannt sind. Dies hilft bei der schnellen Fehlersuche.
- Organisieren Sie mit Ordnern: Während Sie skalieren, werden Sie zahlreiche Dashboards um sich haben. Nutzen Sie die Ordnerfunktion von Grafana, um diese zu kategorisieren.
- Interaktive Legenden: In Grafana können Legenden (Metriknamen) interaktiv sein. Verwenden Sie diese Legenden, um Metriken für eine gezielte Analyse ein- und auszuschalten.
- Konsistente Farbkodierung: Behalten Sie konsistente Farben für bestimmte Metriken in allen Dashboards bei. Das hilft bei der schnelleren Identifizierung.
- Schwellenwerte für Warnungen: Verwenden Sie in Diagrammen visuelle Schwellenwerte oder Linien, welche angeben, ab welchem Punkt ein Alarm ausgelöst wird. Dies gibt ruckartigen Anstiegen und Rückgängen einen Kontext.
Abschließend lässt sich sagen
Bei der Überwachung geht es nicht nur um das Sammeln von Daten, sondern auch um die Umwandlung dieser Daten in verwertbare Ergebnisse. Grafana und Prometheus bieten, sofern sie effektiv genutzt werden, einen ganzheitlichen Überblick über den Zustand und die Leistung einer Anwendung. Durch die Integration mit Plattformen wie Microsoft Teams wird diese Fähigkeit noch ausgebaut, wodurch Echtzeitreaktionen und schnelles Handeln auf diese Erkenntnisse unterstützt werden. Indem Sie Ihre Metriken verstehen, effektive Dashboards erstellen und fundierte Warnmeldungen einrichten, können Sie in Kombination mit Warnmeldungsintegrationen wie Microsoft Teams Probleme präventiv angehen, die Betriebsabläufe sicherstellen und ein hochwertiges Benutzererlebnis aufrechterhalten, während Sie eine nahtlose Anwendungsleistung gewährleisten.

{kind=link}
{kind=link}